
컴파일러란?
: 고수준 언어를 저수준 언어로 번역하는 프로그램
"컴파일러는 복잡한 프로그램일 뿐, 우리가 다룰 수 없는 대단한 프로그램이 아니다." 라는 점을 인지하자.

컴파일러의 작동 원리
// code.c
int a = 1;
int b = 2;
while (a < b) {
b = b - 1;
}간단한 코드 예제(이 소스 파일은 code.c 라고 하자)로 살펴보자.
1. 구문 분석
토큰(token): 항목 + 정보를 결합한 것
컴파일러는 먼저 모든 토큰을 찾는다. 소스 코드를 쪼개 각 항목의 추가 정보를 함께 묶어서 관리한다.
예를 들어, 코드 첫 줄의 int 항목은 이것이 (1)키워드 이며, (2)int 키워드 라는 두 개 정보가 담긴 토큰이 된다.
위 소스 코드를 처리하면 다음과 같이 토큰이 추출되는데, 이 과정이 어휘 분석(lexical analysis)이다.
T_Keyword int
T_Identifier a
T_Assign =
T_Int 1
T_Semicolon ;
T_Keyword int
T_Identifier b
T_Assign =
T_Int 2
T_Semicolon ;
T_While while
T_LeftParen (
T_Identifier a
T_Less <
T_Identifier b
T_RightParen )
T_OpenBrace {
...
컴파일러는 구문에 따라 이 토큰들을 처리하는데, 컴파일러가 while 키워드의 토큰을 찾으면 그에 필요한 토큰이 다음에 오는지(throw syntax error), 이어서 )을 거쳐 {, } 를 처리할 때까지 계속 그 과정을 반복한다.
이 과정을 해석(parsing)이라고 하며, 컴파일러는 구문에 따라 구조를 해석해 내는데 이를 구문 트리로 표현하면 아래와 같다.
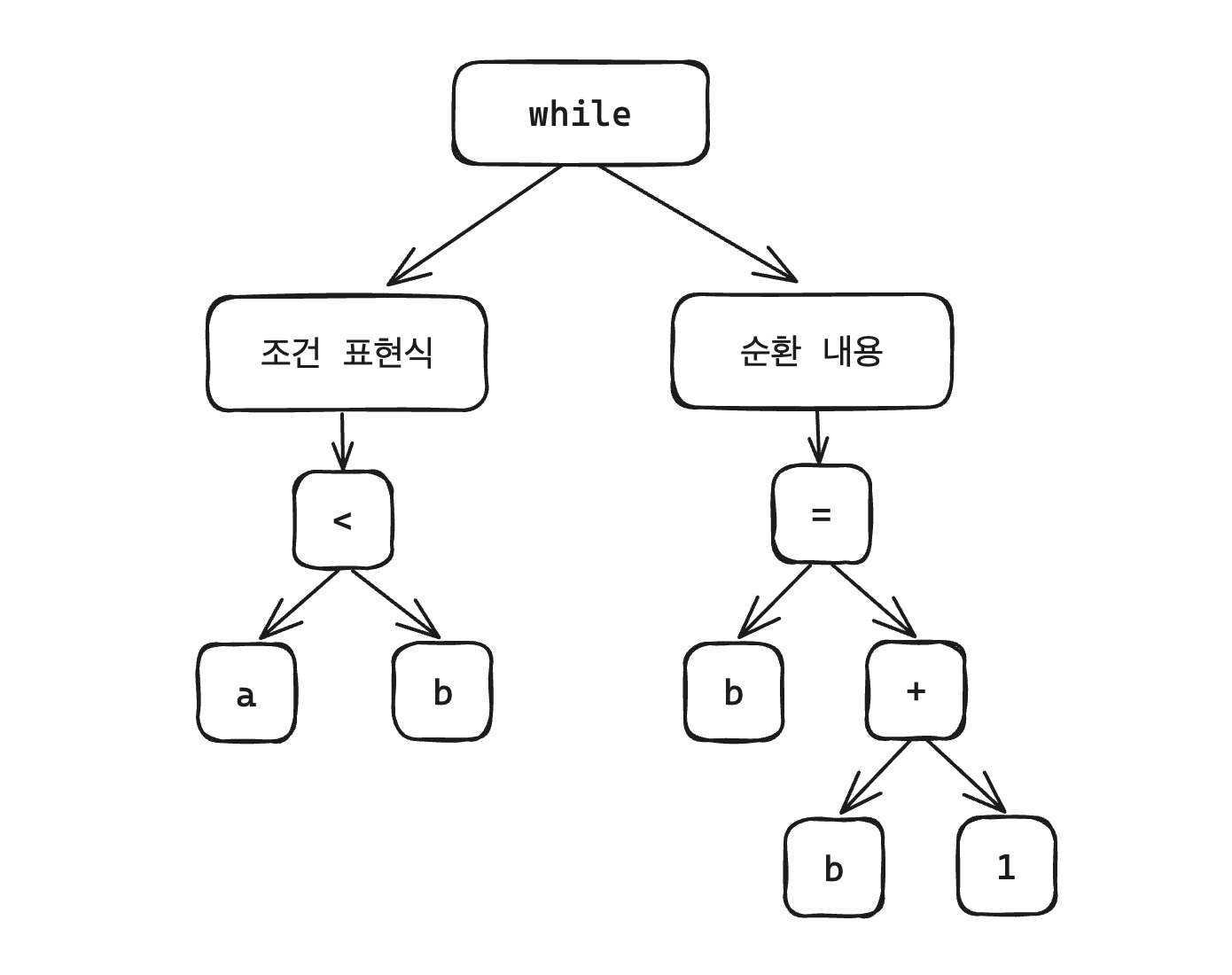
이 일련의 과정을 구문 분석이라고 하며, 구문 트리 생성 후 각 값의 형식을 체크하는 등의 확인을 하는 의미 분석(semantic analysis) 과정을 거쳐 컴파일 오류가 없음을 증명한다.
구문 분석: 구문 규칙에 따라 어휘 분석 → 토큰을 해석 → 구문 트리 생성
2. 코드 변환 = 대상 파일(object file) 생성
컴파일러는 구문 트리를 탐색한 결과를 바탕으로 좀 더 다듬어진 형태의 중간 코드(Intermediate Representation Code, IR Code)를 생성하고,
a = 1
b = 2
goto B
A: b = b - 1
B: if a < b goto A
다시 이 중간 코드를 어셈블리어로 변환 후,
// e.g. x86 어셈블리어 기반의 코드
movl $0x1,-0x4(%rbp) // a = 1
movl $0x2,-0x8(%rbp) // b = 2
jmp B // B로 점프
A: subl $0x1,-0x8(%rbp) // b = b - 1
B: mov -0x4(%rbp),%eax
cmp -0x8(%rbp),%eax // a < b ?
jl A // a < b이면 A로 점프
마지막으로 이 어셈블리어 코드를 기계 명령어로 변환한다.
위의 소스 코드(code.c)가 이 컴파일 과정(축약했지만 실제로는 매우 복잡하다)을 거쳐 생성된 기계 명령어 데이터는 code.o라는 대상 파일로 저장된다.
(.o 의 확장자를 가지는 파일을 대상 파일(object file)이라고 한다.)
모든 소스 파일은 각각의 대상 파일이 있다. 소스 파일이 3개 있다고 가정하면, 대상 파일은 3개가 있다.
우리가 최종적으로 원하는 것은 하나의 실행 파일이므로, 이 3개의 대상 파일을 하나의 실행 파일로 합쳐 주는 링크(link) 작업을 하게 된다.
링커의 동작
3. 링크 = 실행 파일 생성
링커(linker)는 대상 파일을 병합하여 실행 파일을 생성하는 프로그램이다.
링크의 전체 과정은 저자 여러 명이 특정 부분을 담당하여 따로 집필하고, 개별 장을 묶어 책 한권으로 출판하는 것과 유사하다.
심벌 해석 → 실행 파일 생성 → 재배치
심벌: 전역 변수(global variable)와 함수(function)의 이름을 포함하는 모든 변수의 이름
(지역 변수는 모듈 내에서만 사용되어 외부 모듈이 참조하지 않으므로 관심 대상이 아님)
링커는 먼저
(1) 소스 파일에 다른 모듈에서 참조할 수 있는 심벌의 정보,
(2) 소스 파일이 다른 모듈에서 참조하는 심벌의 정보
이 두 가지 정보를 알고 있어야 하는데, 이 정보는 컴파일러가 남겨 준다.
컴파일러가 생성한 대상 파일에는 중요한 두 영역이 포함되어 있다.
- 명령어 부분: 변환된 기계 명령어가 저장됨. 코드 영역(code section)
- 데이터 부분: 전역 변수가 저장됨. 데이터 영역(data section)
컴파일러는 컴파일 과정에서 변수가 선언되어 있으면, 공급과 수요(내가 정의한 심벌, 내가 사용하는 외부 심벌)의 두 가지 내용만 심벌 테이블(symbol table)에 기록해두고 변수의 실제 정의 여부는 신경쓰지 않고 다음 단계로 넘어간다.

참조된 변수 정의를 찾는 일은 링커의 몫.
링커는 공급이 수요를 충족하는지 확인하며, 심벌 해석 과정을 거친다.
(공급은 수요를 초과할 수 있지만, 수요가 공급을 초과하는 상황이 발생하면 오류 = 정의를 찾지 못함)
정적 라이브러리(static library)와 동적 라이브러리(dynamic library)
코드가 많아짐에 따라 컴파일 시간도 점점 길어지고, 사용하는 함수도 찾기 어려워진다.
우리는 별도 코드로 분리하여 사용하는 라이브러리 기능을 활용한다. 이 때 링커가 중요한 역할을 한다.
- 정적 라이브러리
- 소스 파일을 개별적으로 컴파일하고 링크하여 패키지로 묶고, 구현된 모든 함수의 선언을 포함하는 헤더 파일(header file)을 제공하는 것
- 이후 실행 파일을 생성할 때는 자신의 코드만 컴파일하며, 미리 컴파일된 정적 라이브러리는 링크 과정에서 그대로 실행 파일에 복제된다.
- 대상 파일을 한데 모아 각각의 대상 파일에서 데이터 영역과 코드 영역을 결합
- 윈도우의 exe 형식, 리눅스의 elf 파일 같은 실행 파일은 링커가 필요한 대상 파일을 한데 모아 구성한 것.
- 장점
- 컴파일 속도가 빠르다.
- 단점
- 표준 라이브러리를 사용한다면? 모두 동일한 코드와 데이터의 복사본을 가지게 되며 디스크와 메모리를 엄청 낭비함
- 동적 라이브러리
- 공유 라이브러리(shared library), 동적 링크 라이브러리(dynamic linked library)라고도 함
- 윈도우의 DLL 파일, 리눅스의 lib~~~.so 파일
- 참조된 동적 라이브러리 이름, 심벌 테이블, 재배치 정보 등 필수 정보만 실행 파일에 포함된다.
- 정적 라이브러리에 비해 실행 파일의 크기가 확연히 줄어듦
- 이 필수 정보는 동적 링크(dynamic linking)가 일어날 때(실행 시점) 사용된다.
- 동적 링크는 두 가지 방식이 있다.
- 프로그램이 메모리에 적재(loading)될 때
- 적재 중 동적 링크를 사용하려면 실행 파일이 참조하는 동적 라이브러리를 컴파일러에 명시해줘야 한다.
- 프로그램의 실행 시간(runtime) 동안 코드가 직접 동적 링크를 실행
- 실행 파일이 실행될 때까지 어떤 동적 라이브러리에 의존하는지 몰라도 되므로 조금 더 동적인 방식이다.
- 실행 파일 생성 과정에서 실행 파일 내부에 동적 라이브러리 정보가 저장되지 않음
- 프로그램이 메모리에 적재(loading)될 때
- 장점
- 동일한 라이브러리일 경우 복사본 하나만 저장하므로 리소스를 대폭 절약할 수 있다.
- 동적 라이브러리 코드가 수정되어도 해당 라이브러리만 다시 컴파일하면 된다. 실행 파일 컴파일 불필요.
- 플러그인 구현 가능
- 하나의 프로젝트에서 언어 혼합 사용 가능
- 단점
- 임의의 메모리 절대 주소로 참조할 수 없다.
재배치: 심벌의 실행 시 주소 결정
'CS > 밑바닥' 카테고리의 다른 글
| 동기와 비동기, 블로킹과 논블로킹 (0) | 2024.06.26 |
|---|---|
| 콜백 함수와 비동기 프로그래밍 (0) | 2024.06.26 |
| 코루틴(Coroutine) - 스레드보다 가벼운 멀티 태스킹 (0) | 2024.06.18 |
| 프로그램이 실행될 때 - 운영 체제, 프로세스, 스레드 (0) | 2024.06.18 |
| 프로그래머가 코드를 작성할 때 일어나는 일 (1) - 프로그래밍 언어의 탄생 (0) | 2024.06.12 |



