
운영 체제
명확하고 단순한 CPU에서부터 시작된다.
- 메모리에서 명령어를 하나 가져온다. (인출)
- 이 명령어를 실행한 후 다시 돌아간다. (실행)
CPU는 PC 레지스터(register)에 저장된 명령어 주소 기준으로 다음 실행할 명령어를 가져온다.
레지스터: 용량은 매우 작지만 속도는 매우 빠른 일종의 메모리
PC 레지스터가 저장하는 주소는 기본적으로 1씩 자동 증가하며, if-else 또는 함수 호출 등의 명령어를 실행할 때는 점프할 대상의 주소에 따라 PC 레지스터 값을 동적으로 변경한다.

컴파일러가 코드를 실행 파일로 생성하여 디스크에 적재하면, 그 실행파일에서 명령어가 메모리에 저장된다.
프로그램에는 반드시 시작 지점이 있어야 하는데, 이것이 main 함수이다.
최초의 PC 레지스터 값은 이 함수에 대응하는 기계 명령어의 메모리 주소이다.
(실제 상황은 별도의 초기화 과정이 진행됨)
이 방식으로 우리는 수동으로 프로그램을 실행할 수 있게 된다.
프로그램을 적재할 수 있는 적절한 메모리 영역을 찾아 실행 파일을 메모리에 복사한 후, CPU 레지스터를 초기화하고 함수의 진입 포인트(entry point)를 찾아 PC 레지스터에 적재하면 된다!
하지만 이 과정은 매우 복잡하고 번거로우며, 멀티 태스킹이 불가능하다. 모든 하드웨어를 직접 특정 드라이버와 연결하고, 모든 함수, 모든 라이브러리를 직접 구현해야 한다. (옛날에는 정말 이렇게 했다.)
↓ ↓ ↓
오늘날의 프로그램 실행 동작은 이렇다.
메모리 적재: 적재 도구(loader)를 실행하면 프로그램이 메모리에 적재된다.
CPU는 한 번에 한 가지 일만 할 수 있지만, 프로그램 A와 프로그램 B가 동시에 실행되는 것처럼 보이게 하는 방법이 있다.
멀티태스킹(multi-tasking): 프로그램 A와 B를 각각 번갈아서 실행하고 일시중지한다. 이 때 CPU의 전환 빈도가 매우 빨라 두 프로그램이 '동시에 실행'되는 것처럼 보인다.
상황 정보(context): CPU가 실행한 기계 명령어와 CPU 내부의 기타 레지스터 값 등의 상태 값. 이 정보를 저장하면 프로그램을 일시 정지하고 재개할 수 있다.
프로세스(process): 필요한 정보(상황 정보)를 기록할 수 있는 형태의 구조체. 모든 프로그램은 실행된 후 프로세스 형태로 관리된다.
기본적인 멀티태스킹 기능이 동작하는 데 필요한 이 여러 가지 기반 기능의 프로그램을 모아둔 도구(프로그램)를
운영 체제(operationg system) 라고 한다.
프로세스 주소 공간
프로세스 주소 공간(process address space): 프로세스가 실행될 때 사용하는 메모리 공간. 운영 체제의 가상 메모리는 각각의 프로세스가 표준적인 메모리 크기를 독점하여 사용하는 것처럼 보이게 한다.

프로세스 주소 공간은 아래에서부터
- 코드 영역(code segment): 코드를 컴파일한 기계 명령어가 저장됨
- 데이터 영역(data segment): 전역 변수 등
- 힙 영역(heap segment): malloc 함수가 요청을 반환한 메모리, new 함수 등
- 여유 공간: 동적 라이브러리의 코드와 데이터
- 스택 영역(stack segment): 함수의 실행 시간 스택
이런 실행 흐름(flow of execution)을 가진다.
서로 독립적인 두 함수(3분, 4분)를 실행할 때, 프로세스를 활용하여 전체 실행 속도를 높일 수 있다.
1. 단일 프로세스 실행 → 오래 걸림(7분)
2. 다중 프로세스 프로그래밍(multi-process programming) + 프로세스간 통신(inter-process communication) → (4분 + a)
하지만 프로세스 생성에 overhead가 걸리고, 각각 자체적인 주소 공간을 가지고 있어 프로세스 간 통신은 복잡하다.
프로세스에서 스레드로
프로세스의 단점
: 진입 함수가 main 함수 하나밖에 없어 프로세스의 기계 명령어를 한 번에 하나의 CPU에서만 실행할 수 있다.
main 함수는 실행의 첫 번째 함수이지만, 사실 PC 레지스터는 다른 어떤 함수를 가리켜도 상관이 없으며 이를 통해 하나의 프로세스 안에 여러 실행 흐름을 형성해 CPU 여러 개가 한 프로세스의 기계 명령어를 실행하게 할 수 있다.
(∴ 동일한 프로세스 주소 공간을 공유하므로 프로세스 간 통신 불필요)
이 실행 흐름을 스레드(thread) 라고 한다.
스레드: 프로세스 내에서 실행되는 흐름의 단위
이제 스레드 여러 개를 생성하여 여러 개의 함수를 각각 실행할 수 있다. 각 실행 결과는 동일한 프로세스 주소 공간에 속해 있으므로 모든 스레드는 이 변수들을 직접 사용할 수 있고, 프로세스보다 훨씬 가볍고 생성 속도가 빠르다.(스레드 = 경량 프로세스)
스택 프레임(stack frame): 함수가 실행될 때 필요한 정보(매개변수, 지역 변수, 반환 주소 등)
모든 함수는 실행 시에 자신만의 실행 시간 스택 프레임(runtime stack frame)을 가지는데,
이 스택 프레임의 증감(후입선출)이 프로세스 주소 공간의 스택 영역을 형성한다.
스레드 사용으로 하나의 프로세스에 실행 진입점(execution entry point)이 여러 개 존재하고, 동시에 실행 흐름도 여러 개 존재할 수 있게 되었다.
즉, 모든 스레드는 각자 자신만의 스택 영역을 가진다.

다중 스레드(multi-threading): 스레드는 운영 체제 계층에 구현되어 CPU 단일 코어, 다중 코어 상관없이 스레드 여러 개를 생성할 수 있으며, 이는 고성능과 높은 동시성 처리의 기초가 된다.
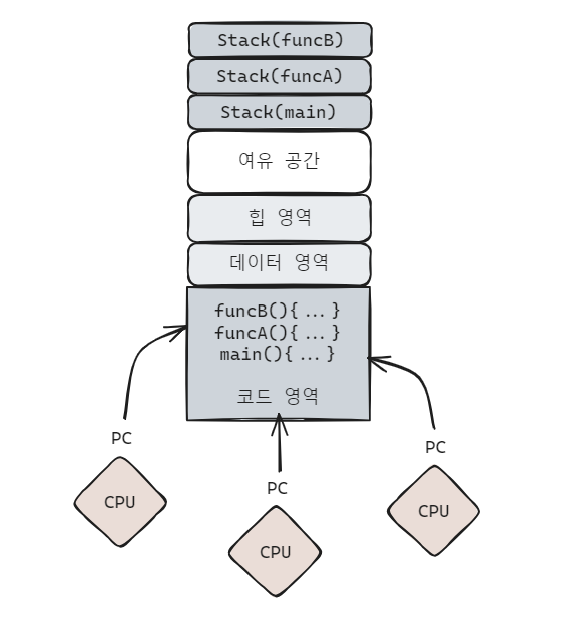
다중 스레드 활용
수명 주기 관점의 요청당 스레드 방식의 단점을 보완하기 위해 리소스 관점의 스레드 풀 방식이 탄생하였다.
- 요청당 스레드(thread-per-request): 특정한 작업에 전용 스레드를 생성하고 처리가 완료되면 스레드를 종료
| 장점 |
|
| 단점 |
|
- 스레드 풀(thread-pool): 스레드 여러 개를 미리 생성, 작업이 생기면 스레드 풀 내의 스레드에 처리 요청
| 장점 |
|
스레드 풀 작업 방식
스레드 풀 내의 스레드에 작업을 전달하는 방식은 대기열(queue) 자료 구조로, 고전적인 생산자-소비자 패턴 흐름에 따른다.
- 작업은 (1)처리할 데이터, (2)데이터를 처리하는 함수 두 부분으로 구성된다.
- 스레드는 작업 대기열(jobs queue)에서 블로킹 상태로 대기
- 생산자가 작업 대기열에 데이터를 기록하면 스레드 풀의 스레드가 깨어나고, 해당 스레드는 작업 대기열에서 구조체를 가져온 후 처리 함수를 실행한다.
- 작업 대기열(task queue)은 공유 리소스이므로 동기화 시 상호 배제 문제 처리가 필요하다.
스레드 수
처리할 작업의 종류(리소스 관점에서)에 따라 스레드 풀에 적합한 스레드 수를 예측할 수 있지만, 정확한 스레드 수를 파악하려면 구체적인 상황과 분석이 필요하다.
- CPU 집약적인 작업(CPU intensive task): 연산 등 외부 입출력에 의존할 필요 없이 처리할 수 있는 작업
- 스레드 수 = CPU의 코어 수
- 입출력 집약적인 작업(input/ouput intensive task): 디스크 입출력이나 네트워크 입출력에 대부분의 시간을 소비하는 작업
- N x (1 + WT ÷ CT)
- N(코어 수), WT(Wait Time, 입출력 대기 시간), CT(Computing Time, 연산 시간)
- WT와 CT가 동일하다고 가정하면 대략 2N개의 스레드 필요
스레드 안전
다중 스레드가 공유 리소스에 접근할 때, 오류를 방지하기 위해서 상호 배제(mutual exclusion)와 동기화(synchronization)을 이용하여 해결해야 한다.
스레드 안전(thread safety): 어떠한 코드가 몇 개의 스레드에서 호출되든 상관없이 올바른 결과가 나오는 것
다중 스레드 사용 → 공공장소에서의 규칙, 공공 자원의 제약을 지켜야 함
스레드 안전 문제의 핵심은 스레드 전용 리소스와 공유 리소스를 구분하는 것!
공유 리소스 vs 스레드 전용 리소스
- 스레드 전용 리소스(thread-private resource): 각 스레드가 가지는 자신만 사용할 수 있는 스택 영역과, 프로그램 카운터, 이외에도 다음 명령어 주소를 저장하는 PC 레지스터, 스택 포인터 등 레지스터 정보(=스레드 상황 정보(thread context))
- 공유 리소스: 여럿 리소스에서 읽고 쓸 수 있는 것. 스레드 전용 리소스를 제외한 나머지는 모두 공유 리소스에 해당한다.
| 영역 | 정보 | 공유 여부 | 작업 | 안전 여부 |
| 코드 영역 | 기계 명령어 | 공유 리소스 | 읽기 전용 | 스레드 안전 |
| 데이터 영역 | 전역 변수 | 모든 스레드 접근 가능, 공유 리소스 e.g. int a = 1; |
쓰기 가능 | |
| 힙 영역 | malloc 함수, new 예약어로 요청하는 메모리 | 포인터(pointer)로 접근 가능, 공유 리소스 | 쓰기 가능 | |
| 스택 영역 | 스레드 상황 정보 | 추상화 측면에서는 스레드 전용 공간이지만, 실제 구현 시 엄밀하게 격리된 전용 공간은 아님. 스택 영역에 보호 방식이 존재하지 않아 타 스레드의 스택 프레임에서 포인터를 가져온다면 스택 영역에 접근 가능 |
쓰기 가능 | |
| 스레드 전용 저장소 | 모든 스레드에서 접근 가능하지만, 변수의 인스턴스는 각각의 스레드에 속함 e.g. __thread int a = 1; |
쓰기 가능하지만 독립적 | 스레드 안전 | |
| 여유 공간 | 동적 라이브러리 코드, 데이터와 파일 정보 | 공유 리소스 |
다중 스레드 코드 작성 시 나머지 영역에서도 스레드 안전하도록 작성하려면 어떻게 해야 할까?
전용 리소스 사용 시: 스레드 안전 달성
공유 리소스 시용 시: 다른 스레드에 영향을 주지 않도록 대기 제약 조건에 맞게 사용하면 스레드 안전 달성 가능
공유 리소스를 사용하는 스레드는 반드시 순서를 따라야 하며, 공유 리소스를 사용하는 작업이 다른 스레드를 방해할 수 없도록 각종 잠금(lock)이나 세마포어(semaphore)같은 장치를 사용하여 순서를 유지한다.
[전용 리소스 사용 시]
1. 스레드 전용 리소스 사용
- 함수가 오로지 스레드 전용 리소스인 지역 변수만 사용한다면, 이 변수는 스레드의 스택 영역에서 관리되기 때문에 스레드 안전하다. 이런 코드를 무상태 함수(stateless function)라고도 한다.
2. 스레드 전용 리소스와 함수 매개변수
- 함수 매개변수를 값으로 전달하는 경우: 스레드 안전
- 함수 매개변수를 포인터로 전달하는 경우: 스레드 안전 X
→ 모든 스레드가 함수를 호출할 때 해당 스레드에 속하는 리소스 주소를 전달하도록 개선 필요
[공유 리소스 사용 시]
3. 전역 변수 사용
- 전역 변수 초기화 후 모든 코드가 해당 변수를 읽기만 하는 경우(Read Only): 스레드 안전
- 읽고 쓰기가 일어나는 경우(Read Write): 스레드 안전 X
→ 잠금 등의 보호 또는 덧셈 작업을 원자성(atomic) 작업으로 설정 필요
4. 스레드 전용 저장소
- 다른 스레드에 영향을 미치지 않음. 스레드 안전
5. 함수 반환값에 따라
- 함수가 값을 반환하는 경우: 스레드 안전
- 함수가 포인터를 반환하는 경우: 스레드 안전 X
→ 이 방법으로 싱글톤 패턴을 구현할 수 있는 단 하나의 예시: static으로 instance 가져오기
6. 스레드 안전이 아닌 코드 호출
- funcA() 에서 스레드 안전이 아닌 함수(func())를 호출하기 전에 잠금으로 보호하면 funcA 함수는 스레드 안전
∴ 스레드 안전 코드를 구현하는 법
- 다중 스레드 프로그래밍 중에는 어떤 리소스라도 최대한 공유하지 않는 것이 첫 번째 원칙
- 스레드 전용 리소스와 스레드 공유 리소스를 파악
- 각각의 상황에 맞는 해결 방안 처리
- 스레드 전용 저장소(thread local storage)
- 전역 리소스를 사용해야 하는 경우 스레드 전용 저장소로 선언 가능한지 확인
- 읽기 전용(read-only)
- 전역 리소스를 사용해야 하는 경우 해당 리소스를 읽기 전용으로 사용해도 되는지 확인
- 원자성 연산(atomic operation)
- 원자성 연산은 도중에 중단되지 않으므로, 잠금 없이 보호됨
- 동기화 시 상호 배제(mutual exclusion in synchronization)
- 프로그래머가 직접 리소스 순서를 유지하는 마지막 단계
- 뮤텍스(mutex), 스핀 잠금(spin lock), 세마포어(semaphore) 등
- 스레드 전용 저장소(thread local storage)
이 글에서 말하는 스레드는 기본적으로 커널 스레드(kernel thread)를 의미하며, 스레드의 생성, 스케줄링, 종료를 모두 운영 체제가 수행하여 프로그래머는 이 과정에 전혀 관여할 수 없다.
운영 체제에 의존하지 않는 상황에서 직접 스레드를 구현할 수 있을까?
다음 글 코루틴에서 그 답을 찾을 수 있다.
'CS > 밑바닥' 카테고리의 다른 글
| 동기와 비동기, 블로킹과 논블로킹 (0) | 2024.06.26 |
|---|---|
| 콜백 함수와 비동기 프로그래밍 (0) | 2024.06.26 |
| 코루틴(Coroutine) - 스레드보다 가벼운 멀티 태스킹 (0) | 2024.06.18 |
| (~ing)프로그래머가 코드를 작성할 때 일어나는 일 (2) - 컴파일러와 링커 (1) | 2024.06.15 |
| 프로그래머가 코드를 작성할 때 일어나는 일 (1) - 프로그래밍 언어의 탄생 (0) | 2024.06.12 |



